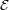 represent the event that
represent the event that  ∑
i=1nXi ≥
∑
i=1nXi ≥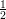 , i.e. the event thet more than half of the coin flips come out
heads.
, i.e. the event thet more than half of the coin flips come out
heads.
YALE UNIVERSITY
DEPARTMENT OF COMPUTER SCIENCE
| CPSC 461b: Foundations of Cryptography | Handout #5 | |
| Yitong Yin | February 26, 2009 | |
Solutions to Problem Set 1
Originally due Thursday, February 19, 2009.
Problem 1 Chernoff bound – application 1
Consider a biased coin with probability p = 1∕3 of landing heads and probability 2∕3 of landing tails. Suppose the coin is flipped some number n of times, and let Xi be a random variable denoting the ith flip, where Xi = 1 means heads, and Xi = 0 means tails. Use the Chernoff bound to determine a value for n so that the probability that more than half of the coin flips come out heads is less that 0.001.
Let represent the event that ∑
i=1nXi ≥, i.e. the event thet more than half of the coin flips come out
heads.
![[ n ] [| n | ]
1-∑ 1- ||1-∑ 1-|| 1-
Pr [E] = Pr n Xi ≥ 2 ≤ Pr ||n Xi - 3 || ≥ 6 .
i=1 i=1](ho052x.png)
Note that E[Xi] = 1∕3. According to the Chernoff bound, the last probability measure is no greater
than 2exp(-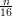 ).
).
Solving the inequality that 2exp(-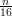 ) < 0.001, we get that n ≥⌈16ln(2000)⌉ = 122.
) < 0.001, we get that n ≥⌈16ln(2000)⌉ = 122.
Problem 2 Chernoff bound – application 2
At the Yale-Harvard hockey game on February 6, Yale made 50 shots on the Harvard goal and scored 5 times, whereas Harvard made 15 shots on the Yale goal and scored only once. Assume that both teams had equally good goalies and that for each team, the probability is p = 0.1 of a shot scoring a goal. Clearly, the expected number of goals is np, where n is the number of shots. For Yale, the actual number of goals g exactly matched the expectation, but for Harvard with 15 shots, the actual number of goals (1) fell considerably short of the expected number (1.5).
The purpose of this problem is to assess how unusual it is that Harvard scored fewer than the expected number of goals given the number of shots on the goal and the assumed success probability of each shot. In the following, let n = 15, g = 1, p = 0.1, and q = Pr[# goals after n shots ≤ g]. We wish to find a “good” upper bound on q.
Let Xi  {0,1} be the random variable that indicates whether the ith shot of Harvard scores.
{0,1} be the random variable that indicates whether the ith shot of Harvard scores.
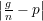 . It is easy to verify that when
. It is easy to verify that when 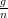 < p, the event that ∑
i=1nXi ≤ g implies
that
< p, the event that ∑
i=1nXi ≤ g implies
that 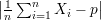 ≥ ϵ.
≥ ϵ.
When n = 15,g = 1 and p = 0.1, it holds that 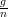 < p and ϵ =
< p and ϵ = 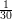 . Applying the Chernoff bound,
. Applying the Chernoff bound,
![[ ]
∑n
q = Pr Xi ≤ g
[ i=|1 | ]
||1∑n ||
≤ Pr ||n- Xi - p|| ≥ ϵ
( i=1 )
---ϵ2n---
= 2exp - 2p(1 - p)
≤ 1.823.](ho0510x.png)
![[ ]
∑n
q = Pr Xi ≤ 1
[ i=1 ] [ ]
∑n ∑n
= Pr Xi = 0 + Pr Xi = 1
i=1 i=1
n (n) n- 1
= (1- p) + 1 p(1- p)
≈ 0.5490.](ho0511x.png)
Let M be a ppTM that accepts a language L and runs in time p(n) for some polynomial p(⋅). Let x be an input string of length n and r a random choice string of length p(n) ≫ n. Let δ(x,r) = 1 if M(x,r), the output of M with coin toss sequence r, gives the correct answer about x’s membership in L, and let δ(x,r) = 0 otherwise. Suppose Pr[M(Un,Up(n)) is correct] = 1 - 2∕2n.
How large can we make the success probability of M(Un,r) by setting the second input of M to a fixed string r? That is, what is the best lower bound on
![marx P r[M (Un, r)]](ho0512x.png)
that is implied by the given information, where maxr is taken over all binary strings of length p(n)?
[Note: This problem generalizes a fact used in the proof of Theorem 4, section 11, lecture notes 3.]
The naïve lower bound is 1 - 2∕2n, since the maximum can not be smaller than the average. We will show that this is the best general lower bound by constructing a case where maxr Pr[M(Un,r) is correct] = 1 - 2∕2n.
Denote δ(x,r) as a 2n × 2p(n) 0-1 matrix. Assign to each column of δ(x,r) exactly 2 zeroes. For every r, it holds that Pr[δ(Un,r)] = (2n - 2)∕2n = 1 - 2∕2n.
Therefore it satisfies the above constraint that that Pr[δ(Un,Up(n))] = 1 - 2∕2n. The maximum is maxr Pr[δ(Un,r)] = 1 - 2∕2n.
Problem 4 One-way functions and the 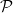 -versus-
-versus-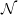 question
question
[Textbook, Chapter 2, Exercise 3.]
The function f(π,ϕ,τ), where π represents the first n∕2 bits and (ϕ,τ) is the input of fsat, is defined as
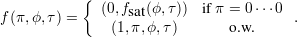
It is obvious that f is polynomial-time-computable because both branches in the definition are polynomial-time-computable and the condition can be verified in linear time. Claim 1 holds.
Suppose that A is such a polynomial-time algorithm that always inverts f. Let B be such an algorithm whose input domain is the range of fsat and we define that B(y) = A(0,y). It is trivial that B is also polynomial-time. For every y in the range of fsat, according to the definition of f, B(y) will output some (π,ϕ,τ) such that (0,fsat(ϕ,τ)) = (0,y), i.e. fsat(ϕ,τ) = y, thus B is a polynomial-time algorithm which always inverts fsat, which is contra to the assumption that NP≠P . Claim 2 holds.
Let C be such a program that C(y) outputs all but the first bit of y if the first bit of y is 1, and outputs an arbitrary string if otherwise. It is easy to see that C is a polynomial-time algorithm that inverts f when the first bit of y is 1. The probability that C fails to invert f can be written as
![-1
Pr [C fails ] = Pr [C (f(Un)) ⁄∈ f (f(Un))]
≤ Pr [the first bit of f(Un ) is 0]
= Pr [the first n∕2 bits of U are all 0s]
- n n
= 2 2.](ho0514x.png)