March 4 - Learning¶
from learning import *
from notebook import *

 Versicolor
Versicolor
 Virginia
Virginia
MACHINE LEARNING OVERVIEW¶
In this notebook, we learn about agents that can improve their behavior through diligent study of their own experiences.
An agent is learning if it improves its performance on future tasks after making observations about the world.
There are three types of feedback that determine the three main types of learning:
- Supervised Learning:
In Supervised Learning the agent observes some example input-output pairs and learns a function that maps from input to output.
Example: Let's think of an agent to classify images containing cats or dogs. If we provide an image containing a cat or a dog, this agent should output a string "cat" or "dog" for that particular image. To teach this agent, we will give a lot of input-output pairs like {cat image-"cat"}, {dog image-"dog"} to the agent. The agent then learns a function that maps from an input image to one of those strings.
- Unsupervised Learning:
In Unsupervised Learning the agent learns patterns in the input even though no explicit feedback is supplied. The most common type is clustering: detecting potential useful clusters of input examples.
Example: A taxi agent would develop a concept of good traffic days and bad traffic days without ever being given labeled examples.
- Reinforcement Learning:
In Reinforcement Learning the agent learns from a series of reinforcements—rewards or punishments.
Example: Let's talk about an agent to play the popular Atari game—Pong. We will reward a point for every correct move and deduct a point for every wrong move from the agent. Eventually, the agent will figure out its actions prior to reinforcement were most responsible for it.
DATASETS¶
For the following tutorials we will use a range of datasets, to better showcase the strengths and weaknesses of the algorithms. The datasests are the following:
Fisher's Iris: Each item represents a flower, with four measurements: the length and the width of the sepals and petals. Each item/flower is categorized into one of three species: Setosa, Versicolor and Virginica.
Zoo: The dataset holds different animals and their classification as "mammal", "fish", etc. The new animal we want to classify has the following measurements: 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 4, 1, 0, 1 (don't concern yourself with what the measurements mean).
To make using the datasets easier, we have written a class, DataSet, in learning.py. The tutorials found here make use of this class.
Let's have a look at how it works before we get started with the algorithms.
Intro¶
A lot of the datasets we will work with are .csv files (although other formats are supported too). We have a collection of sample datasets ready to use on aima-data. Two examples are the datasets mentioned above (iris.csv and zoo.csv). You can find plenty datasets online, and a good repository of such datasets is UCI Machine Learning Repository.
In such files, each line corresponds to one item/measurement. Each individual value in a line represents a feature and usually there is a value denoting the class of the item.
You can find the code for the dataset here:
psource(DataSet)
Class Attributes¶
examples: Holds the items of the dataset. Each item is a list of values.
attrs: The indexes of the features (by default in the range of [0,f), where f is the number of features). For example,
item[i]returns the feature at index i of item.attrnames: An optional list with attribute names. For example,
item[s], where s is a feature name, returns the feature of name s in item.target: The attribute a learning algorithm will try to predict. By default the last attribute.
inputs: This is the list of attributes without the target.
values: A list of lists which holds the set of possible values for the corresponding attribute/feature. If initially
None, it gets computed (by the functionsetproblem) from the examples.distance: The distance function used in the learner to calculate the distance between two items. By default
mean_boolean_error.name: Name of the dataset.
source: The source of the dataset (url or other). Not used in the code.
exclude: A list of indexes to exclude from
inputs. The list can include either attribute indexes (attrs) or names (attrnames).
Class Helper Functions¶
These functions help modify a DataSet object to your needs.
sanitize: Takes as input an example and returns it with non-input (target) attributes replaced by
None. Useful for testing. Keep in mind that the example given is not itself sanitized, but instead a sanitized copy is returned.classes_to_numbers: Maps the class names of a dataset to numbers. If the class names are not given, they are computed from the dataset values. Useful for classifiers that return a numerical value instead of a string.
remove_examples: Removes examples containing a given value. Useful for removing examples with missing values, or for removing classes (needed for binary classifiers).
iris = DataSet(name="iris")
iris.examples
len(iris.examples)
values is a list of lists of the possible values for each attribute, including the targets
iris.values
len(iris.values)
list(map(len,iris.values))
iris.values[4]
iris.distance
dir(iris)
print(iris.examples[0])
print(iris.inputs)
Which correctly prints the first line in the csv file and the list of attribute indexes.
When importing a dataset, we can specify to exclude an attribute (for example, at index 1) by setting the parameter exclude to the attribute index or name.
iris2 = DataSet(name="iris",exclude=[1])
print(iris2.inputs)
Attributes¶
Here we showcase the attributes.
First we will print the first three items/examples in the dataset.
print(iris.examples[:3])
Then we will print attrs, attrnames, target, input. Notice how attrs holds values in [0,4], but since the fourth attribute is the target, inputs holds values in [0,3].
print("attrs:", iris.attrs)
print("attrnames (by default same as attrs):", iris.attrnames)
print("target:", iris.target)
print("inputs:", iris.inputs)
Now we will print all the possible values for the first feature/attribute.
print(iris.values[0])
Finally we will print the dataset's name and source. Keep in mind that we have not set a source for the dataset, so in this case it is empty.
print("name:", iris.name)
print("source:", iris.source)
A useful combination of the above is dataset.values[dataset.target] which returns the possible values of the target. For classification problems, this will return all the possible classes. Let's try it:
print(iris.values[iris.target])
Helper Functions¶
We will now take a look at the auxiliary functions found in the class.
First we will take a look at the sanitize function, which sets the non-input values of the given example to None.
In this case we want to hide the class of the first example, so we will sanitize it.
Note that the function doesn't actually change the given example; it returns a sanitized copy of it.
print("Sanitized:",iris.sanitize(iris.examples[0]))
print("Original:",iris.examples[0])
Currently the iris dataset has three classes, setosa, virginica and versicolor. We want though to convert it to a binary class dataset (a dataset with two classes). The class we want to remove is "virginica". To accomplish that we will utilize the helper function remove_examples.
iris2 = DataSet(name="iris")
iris2.remove_examples("virginica")
print(iris2.values[iris2.target])
len(iris2.examples)
We also have classes_to_numbers. For a lot of the classifiers in the module (like the Neural Network), classes should have numerical values. With this function we map string class names to numbers.
print("Class of first example:",iris2.examples[0][iris2.target])
iris2.classes_to_numbers()
print("Class of first example:",iris2.examples[0][iris2.target])
As you can see "setosa" was mapped to 0.
Finally, we take a look at find_means_and_deviations. It finds the means and standard deviations of the features for each class.
means, deviations = iris.find_means_and_deviations()
print("Setosa feature means:", means["setosa"])
print("Versicolor mean for first feature:", means["versicolor"][0])
print("Setosa feature deviations:", deviations["setosa"])
print("Virginica deviation for second feature:",deviations["virginica"][1])
IRIS VISUALIZATION¶
Since we will use the iris dataset extensively in this notebook, below we provide a visualization tool that helps in comprehending the dataset and thus how the algorithms work.
We plot the dataset in a 3D space using matplotlib and the function show_iris from notebook.py. The function takes as input three parameters, i, j and k, which are indices to the iris features, "Sepal Length", "Sepal Width", "Petal Length" and "Petal Width" (0 to 3). By default we show the first three features.
iris = DataSet(name="iris")
show_iris()
show_iris(0, 1, 3)
show_iris(1, 2, 3)



You can play around with the values to get a good look at the dataset.
DISTANCE FUNCTIONS¶
In a lot of algorithms (like the k-Nearest Neighbors algorithm), there is a need to compare items, finding how similar or close they are. For that we have many different functions at our disposal. Below are the functions implemented in the learning.py module:
Manhattan Distance (manhattan_distance)¶
One of the simplest distance functions. It calculates the difference between the coordinates/features of two items. To understand how it works, imagine a 2D grid with coordinates x and y. In that grid we have two items, at the squares positioned at (1,2) and (3,4). The difference between their two coordinates is 3-1=2 and 4-2=2. If we sum these up we get 4. That means to get from (1,2) to (3,4) we need four moves; two to the right and two more up. The function works similarly for n-dimensional grids.
def manhattan_distance(X, Y):
return sum([abs(x - y) for x, y in zip(X, Y)])
distance = manhattan_distance([1,2], [3,4])
print("Manhattan Distance between (1,2) and (3,4) is", distance)
Euclidean Distance (euclidean_distance)¶
Probably the most popular distance function. It returns the square root of the sum of the squared differences between individual elements of two items.
def euclidean_distance(X, Y):
return math.sqrt(sum([(x - y)**2 for x, y in zip(X,Y)]))
distance = euclidean_distance([1,2], [3,4])
print("Euclidean Distance between (1,2) and (3,4) is", distance)
Hamming Distance (hamming_distance)¶
This function counts the number of differences between single elements in two items. For example, if we have two binary strings "111" and "011" the function will return 1, since the two strings only differ at the first element. The function works the same way for non-binary strings too.
def hamming_distance(X, Y):
return sum(x != y for x, y in zip(X, Y))
distance = hamming_distance(['a','b','c'], ['a','b','b'])
print("Hamming Distance between 'abc' and 'abb' is", distance)
Mean Boolean Error (mean_boolean_error)¶
To calculate this distance, we find the ratio of different elements over all elements of two items. For example, if the two items are (1,2,3) and (1,4,5), the ratio of different/all elements is 2/3, since they differ in two out of three elements.
Note: this is the default distance metric for the DataSet class.
def mean_boolean_error(X, Y):
return mean(int(x != y) for x, y in zip(X, Y))
distance = mean_boolean_error([1,2,3], [1,4,5])
print("Mean Boolean Error Distance between (1,2,3) and (1,4,5) is", distance)
Mean Error (mean_error)¶
This function finds the mean difference of single elements between two items. For example, if the two items are (1,0,5) and (3,10,5), their error distance is (3-1) + (10-0) + (5-5) = 2 + 10 + 0 = 12. The mean error distance therefore is 12/3=4.
def mean_error(X, Y):
return mean([abs(x - y) for x, y in zip(X, Y)])
distance = mean_error([1,0,5], [3,10,5])
print("Mean Error Distance between (1,0,5) and (3,10,5) is", distance)
Mean Square Error (ms_error)¶
This is very similar to the Mean Error, but instead of calculating the difference between elements, we are calculating the square of the differences.
def ms_error(X, Y):
return mean([(x - y)**2 for x, y in zip(X, Y)])
distance = ms_error([1,0,5], [3,10,5])
print("Mean Square Distance between (1,0,5) and (3,10,5) is", distance)
Root of Mean Square Error (rms_error)¶
This is the square root of Mean Square Error.
def rms_error(X, Y):
return math.sqrt(ms_error(X, Y))
distance = rms_error([1,0,5], [3,10,5])
print("Root of Mean Error Distance between (1,0,5) and (3,10,5) is", distance)
PLURALITY LEARNER CLASSIFIER¶
Overview¶
The Plurality Learner is a simple algorithm, used mainly as a baseline comparison for other algorithms. It finds the most popular class in the dataset and classifies any subsequent item to that class. Essentially, it classifies every new item to the same class. For that reason, it is not used very often, instead opting for more complicated algorithms when we want accurate classification.
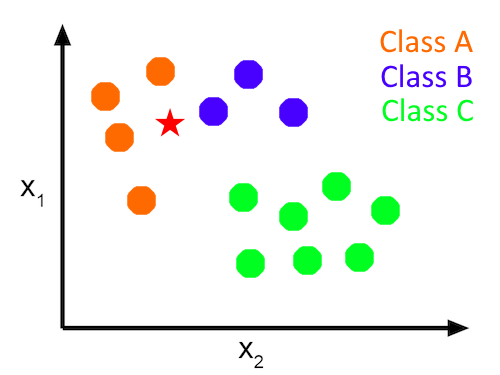
Let's see how the classifier works with the plot above. There are three classes named Class A (orange-colored dots) and Class B (blue-colored dots) and Class C (green-colored dots). Every point in this plot has two features (i.e. X1, X2). Now, let's say we have a new point, a red star and we want to know which class this red star belongs to. Solving this problem by predicting the class of this new red star is our current classification problem.
The Plurality Learner will find the class most represented in the plot. Class A has four items, Class B has three and Class C has seven. The most popular class is Class C. Therefore, the item will get classified in Class C, despite the fact that it is closer to the other two classes.
Implementation¶
Below follows the implementation of the PluralityLearner algorithm:
psource(PluralityLearner)
It takes as input a dataset and returns a function. We can later call this function with the item we want to classify as the argument and it returns the class it should be classified in.
The function first finds the most popular class in the dataset and then each time we call its "predict" function, it returns it. Note that the input ("example") does not matter. The function always returns the same class.
Often used in predicting political preference.¶
If Biden got 48% of the vote, given a new voter V, we predict that V would vote for Biden.
Example¶
For this example, we will not use the Iris dataset, since each class is represented the same. This will throw an error. Instead we will use the zoo dataset.
zoo = DataSet(name="zoo")
pL = PluralityLearner(zoo)
print(pL([1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 4, 1, 0, 1]))
The output for the above code is "mammal", since that is the most popular and common class in the dataset.