 ℕ, Y = {Y n}nℕ be probability ensembles. X, Y are statistically close if their statistical
difference Δ(n) is negligible, where
ℕ, Y = {Y n}nℕ be probability ensembles. X, Y are statistically close if their statistical
difference Δ(n) is negligible, where
YALE UNIVERSITY
DEPARTMENT OF COMPUTER SCIENCE
| CPSC 461b: Foundations of Cryptography | Notes 11 (rev. 1) | |
| Professor M. J. Fischer | February 17, 2009 | |
Lecture Notes 11
Let X = {Xn}nℕ, Y = {Y n}nℕ be probability ensembles. X, Y are statistically close if their statistical
difference Δ(n) is negligible, where
![1∑
Δ (n) = 2 |P r[Xn = α] - Pr[Yn = α]|.
α](ln110x.png)
Here’s the proof that I only sketched in class.
Proof: We prove the contrapositive. Suppose X, Y are not indistinguishable in polynomial time. Then there exists a p.p.t. algorithm D and a positive polynomial p(⋅) such that for infinitely many n,
![|Pr[D (Xn, 1n) = 1]- P r[D (Yn,1n) = 1]| ≥ -1--
p(n)](ln111x.png) | (1) |
For α a length-n string, let p(α)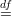 Pr[D(α,1n) = 1]. Then
Pr[D(α,1n) = 1]. Then
![n ∑
P r[D (Xn, 1 ) = 1] = p(α) ⋅Pr[Xn = α ].
α](ln113x.png) | (2) |
![∑
Pr[D (Yn, 1n) = 1] = p(α) ⋅Pr[Yn = α].
α](ln114x.png) | (3) |
Plugging (2) and (3) into (1) gives
![∑ ∑
-1-- ≤ | p(α)⋅P r[Xn = α ]- p(α) ⋅Pr[Yn = α]| (4)
p(n) α α
∑
= | p(α)⋅(P r[Xn = α]- P r[Yn = α])| (5)
∑ α
≤ p(α)⋅|P r[Xn = α]- P r[Yn = α]| (6)
α
≤ ∑ |Pr[X = α ]- Pr[Y = α]| (7)
n n
α
= 2Δ(n). (8)](ln115x.png)
The converse to theorem 1 does not hold.
Theorem 2 There exists X = {Xn}nℕ that is indistinguishable from the uniform ensemble
U = {Un}nℕ in polynomial time, yet X and U are not statistically close. Furthermore, Xn assigns
all probability mass to a set Sn consisting of at most 2n∕2 strings of length n.
Proof: We construct the ensemble X = {Xn}nℕ by choosing for each n a set Sn ⊆{0,1}n of
cardinality N = 2n∕2 and letting Xn be the uniformly distributed on Sn. Thus, Pr[Xn = α] = 1∕N
for α  Sn, and Pr[Xn = α] = 0 for α ⁄ Sn.
Sn, and Pr[Xn = α] = 0 for α ⁄ Sn.
The fact that X, U are not statistically close is immediate from the above. Using the facts that 2n = N2 and |Sn| = N, and |Sn| = N2 - N, we get
![∑
Δ(n ) = 1- |Pr[Xn = α ]- Pr[Un = α ]|
2 α
( )
1-( ∑ -1- ∑ 1--)
= 2 |P r[Xn = α ]- N 2|+ |P r[Xn = α]- N 2|
(α∈Sn α⁄∈Sn)
∑ ∑
= 1-( | 1-- 1--|+ |0- 1--|)
2 α∈Sn N N2 α⁄∈Sn N2
( ( ) )
= 1-⋅ N ⋅ -1 - -1- + (N 2 - N )-1-
2 N N 2 N 2
1-
= 1- N](ln116x.png)
The proof in the textbook supplies the low-level details needed to establish this theorem, but it is a little unclear about the construction itself, particularly about how the set Sn is chosen.
We wish to choose a set Sn for which the corresponding distribution Xn is indistinguishable from Un by every polynomial size circuit C. We do this by diagonalizing over all circuits of size 2n∕8. We start with all size 2N subsets of {0,1}n as candidates for Sn. For each such circuit C, we discard from consideration all candidates on which C is too successful at distinguishing the corresponding ensemble from uniform. By a counting argument, we show that not very many candidates get thrown out at each stage—so few in fact that there are still candidates left after all of the size 2n∕8 circuits have been considered. We choose any remaining candidate for Sn and conclude that no size 2n∕8 circuit is very successful at distinguishing Xn from Un.
More precisely, here’s how to determine which candidates to discard. First, consider an n-input circuit C with at most 2n∕8 gates. Let pC be C’s expected output on uniformly chosen inputs. Then C(x) = 1 for a pC fraction of all length n strings, and C(x) = 0 for the remainder.
Let 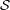 n = {S ⊆{0,1}n∣|S| = 2N}. This is the initial family of candidate sets. Let fC : n →{0,1},
where
n = {S ⊆{0,1}n∣|S| = 2N}. This is the initial family of candidate sets. Let fC : n →{0,1},
where
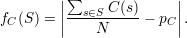
Thus, fC(S) is the amount that the average value of C(s) taken over strings s S differs from the average
value of C(u) taken over all length-n strings u. By the law of large numbers, we would expect fC(S) to be
very small with high probability for randomly chosen S . Call a set S bad for C if fC(S) ≥ 2-n∕8.
Using the Chernoff bound, one shows that the fraction of sets S n that are bad for C is less than 2-2n∕4
.
(Details are in the book.)
Next, one argues that there are at most 22n∕4
circuits of size 2n∕8. (This is by a counting argument.
Details are not in the book and should be verified.) From this, it follows that there is at least one set
Sn n which is not bad for any such circuit. Fix such a set.
Now, let Xn be uniformly distributed over Sn. Observe that the following three quantities are all the
same: the expected value of C(Xn), Pr[C(Xn) = 1], and ∑
sSC(s)∕N. Hence, for all circuits C of size
at most 2n∕8, we have |Pr[C(Xn) = 1] -Pr[C(Un) = 1]| = fC(Sn) < 2-n∕8, which grows more slowly
than 1∕p(n) for any polynomial p(⋅). We conclude that the probabilistic ensembles U and X are
indistinguishable by polynomial-size circuits, which also implies polynomial-time indistinguishability by
probabilistic polynomial-time Turing machines. __
We remark that a consequence of theorem 2 is that the set Sn on which Xn has non-zero probability
mass cannot be recognized in polynomial time. Assume to the contrary that it could be recognized by some
polynomial time algorithm A, that is, A(x) = 1 if x Sn and A(x) = 0 otherwise.. Then A itself would
distinguish Xn from Un. Clearly, Pr[A(Xn) = 1] = 1 but Pr[A(Un) = 1] = |Sn|∕2n. Since |Sn| = 2n∕2,
these two probabilities differ by 1 -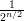 which is greater than
which is greater than 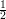 for all sufficiently large n. (Note that the
constant 2 is also a polynomial!)
for all sufficiently large n. (Note that the
constant 2 is also a polynomial!)
The definition of polynomial time indistinguishability given in section 26 gives the distinguishing algorithm D a single random sample from either X or Y and compare the two probabilities of it outputting a 1. We can generalize that definition in a straightforward way by providing D with multiple samples, as long as the number of samples is itself bounded by a polynomial m(n). If the difference in output probabilities in this case is a negligible function, we say that X, Y are indistinguishable by polynomial-time sampling. See Definition 3.2.4 of the textbook for details
Giving D multiple samples allows for new possible distinguishing algorithms. For example, consider the algorithm Eq(x,y) that outputs 1 if x = y and 0 otherwise. Eq able to distinguish the ensemble X of Theorem 2 from U. Let’s analyze the probabilities.
![P r[Eq (X1 ,X2 ) = 1] = 1
n n N](ln1110x.png)
since no matter what value Xn1 assumes, there is a 1∕N chance that the second (independent) sample is equal to it. (Recall that N = 2n∕2.) On the other hand,
![1 2 -1-
Pr[Eq (U n,Un ) = 1] = N 2.](ln1111x.png)
The difference of these two probabilities is clearly non-negligible.
However, it turns out that multiple samples are only helpful in cases such as this where at least one of the distributions cannot be constructed in polynomial time, as we shall see.
We say that an ensemble X = {Xn}nℕ is polynomial-time constructible if there exists a
polynomial-time probabilistic algorithm S such that the output distribution S(1n) and Xn are identically
distributed.
Theorem 3 Let probability ensembles X, Y be indistinguishable in polynomial time, and suppose both are polynomial-time constructible. Then X, Y are indistinguisable by polynomial-time sampling.
Proof: The proof is an example of the hybrid technique, also sometimes called an interpolation proof. Here’s the outline of it.
Assume X, Y are distinguishable by D using m = m(n) samples. Let Xn(1),…,Xn(m) be independent random variables identically distributed to Xn and similarly for Y . Let
![p(X ) = P r[D (X (1),...,X (m )) = 1],
n n](ln1112x.png)
and let
![p(Y ) = P r[D(Yn(1),...,Y(nm)) = 1].](ln1113x.png)
By assumption, D can distinguish X, Y , so the difference δ(n) = |p(x) = p(y)| is non-negligible.
We now construct a sequence of hybrid m-tuples of random variables for k = 0,…,m:
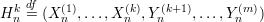
Clearly, Hn0 consists of all Y ’s, and Hnm consists of all X’s. Hence, D distinguishes between Hn0 and Hnm with probability δ(n).
Now let δk(n) be the absolute value of the difference in D’s probability of outputting a 1 given Hnk and Hnk+1. It is easily seen that ∑ k=0m-1δk(n) ≥ δ(n); hence, for some particular value of k = k0,
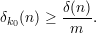
We now describe a single-sample distinguisher D′. On input α, it first chooses a random number k from {0,…,m-1} Next, it generates k independent random numbers x1,…,xk distributed according to Xn and m - k - 1 random numbers yk+2,…,ym distributed according to Y n. It can do this by the assumption that X and Y are polynomial-time constructible. It then constructs h = (x1,…,xk,α,yk+2,…,ym), runs D(h), and outputs the result.
Note that h is distributed according to Hnk if α was chosen according to Y , and h is distributed according to Hnk+1 if α was chosen according to X. Thus, the probability that D′ outputs 1 given a sample from X or a sample from Y is at least 1∕m, the probability that D′ chooses k = k0, times δk0(n). Hence, D′ distinguishes with probability difference at least δ(n)∕m2, which contradicts the assumption that X, Y are indistinguishable in polynomial time. __