
YALE UNIVERSITY
DEPARTMENT OF COMPUTER SCIENCE
| CPSC 467a: Cryptography and Computer Security | Notes 5 (rev. 1) | |
| Professor M. J. Fischer | September 21, 2006 | |
Lecture Notes 5
The Data Encryption Standard is a block cipher that operates on 64-bit blocks and uses a 56-bit key. It was the standard algorithm for data encryption for over 20 years until it became widely acknowledged that the key length was too short and it was subject to brute force attack. (The new standard used the Rijndael algorithm and is called AES.)
DES is based on a Feistel network. This is a general method for building an invertible function from any function f that scrambles bits. It consists of some number of stages. Each stage i maps a pair of 32-bit words (Li,Ri) to a new pair (Li+1,Ri+1). By applying the stages in sequence, a t-stage network maps (L0,R0) to (Lt,Rt). The (L0,R0) is the plaintext, and (Lt,Rt) is the corresponding ciphertext.
Each stage works as follows:
|
| (1) |
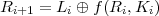 | (2) |
Here, Ki is a subkey, which is generally derived in some systematic way from the master key k.
The security of a Feistel-based code lies in the construction of the function f and in the method for producing the subkeys Ki, However, the invertibility follows just from properties of ⊕.
The inversion problem is to find (Li,Ri) given (Li+1,Ri+1). Equation 1 gives us Ri. Knowing Ri and Ki, we can compute f(Ri,Ki). We can then solve equation 2 to get
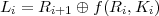
DES uses a 16 stage Feistel network. The pair L0R0 is constructed from a 64-bit message by a fixed initial permutation IP. The ciphertext output is obtained by applying IP-1 to R16L16.
The scrambling function f(Ri,Ki) operates on a 32-bit data block and a 48-bit key block. Thus, a total of 48 × 16 = 768 key bits are used. They are all derived in a systematic way from the 56-bit primary key and are far from independent of each other.
The scrambling function f(Ri,Ki) is the heart of DES. It operates on a 32-bit data block and a 48-bit key block. Thus, a total of 48 × 16 = 768 key bits are used. They are all derived in a systematic way from the 56-bit master key k and are far from independent of each other. In a little more detail, k is split into two 28-bit pieces C and D. At each stage, C and D are rotated by one or two bit positions. Subkey Ki is then obtained by applying a fixed permutation (transposition) to CD. (See Table 3.4c of the text.)
The scrambling function itself is rather involved. However, at its heart are eight “S-boxes”. These are boxes with 6 binary inputs c0,x1,x2,x3,x4,c1 and 4 binary outputs y1,y2,y3,y4. Each computes some fixed function in {0,1}6 →{0,1}4. Moreover, each S-box has the very special property that for each of the four possible ways of fixing the values of (c0,c1) to Boolean constants, the resulting function on the remaining four inputs x1,…,x4 is a permutation from {0,1}4 →{0,1}4. Therefore, we can regard an S-box as performing a substitution on four-bit “characters”, where the substitution performed depends both on the structure of the particular S-box and on the values of its “control inputs” c0 and c1. The eight S-boxes are all different and are specified by their truth tables.
The S-boxes together have a total of 48 input lines. Each of these lines is the output of a corresponding ⊕-gate. One input of each of these ⊕-gates is connected to a corresponding bit of the 48-bit subkey Ki. (This is the only place that the key enters into DES.) The other input of each ⊕-gate is connected to one of the 32 bits of the first argument of f. Since there are 48 ⊕-gates and only 32 bits in the first argument to f, some of those bits get used more than once. The mapping of input bits to ⊕-gates is called the expansion permutation E and is given by Table 3.2(c) in the text. By looking at the table, one sees that the ⊕-gates connected to the six inputs c0,x1,x2,x3,x4,c1 for S-box 1 are in turn connected to the input bits 32,1,2,3,4,5, respectively. For S-box 2, they go to bits 4,5,6,7,8,9, etc. Thus, inputs bits 1,4,5,8,9,…28,29,32 are each used twice, and the remaining input bits are each used once.
Finally, the 32 bits of output from the S-boxes are passed through a fixed permutation P (transposition) that spreads out the output bits. The outputs of a single S-box at one stage of DES become inputs to several different S-boxes at the next stage. This helps provide the desirable “avalanche” effect described in the text.
We have mentioned previously that DES is vulnerable to a brute force attack because of its small key size of only 56 bits. However, it has turned out to be remarkably resistant to two recently discovered cryptanalysis attacks, differential cryptanalysis and linear cryptanalysis. The former can break DES using “only” 247 chosen ciphertext pairs. The latter works with 243 chosen plaintext pairs. Neither attack is feasible in practice.
DES has now been replaced as a national standard by the new AES (Advanced Encryption Standard), based on the Rijndael algorithm, developed by two Dutch computer scientists. AES supports key sizes of 128, 192, and 256 bits and works on 128-bit blocks. We will say more about it later in the course.
A natural way to attempt to increase the security of a cryptosystem is double encryption. Each message is encrypted twice using two different keys k1 and k2. That is, c = Ek2(Ek1(m). Now, a brute force attack would require trying all possible keys k1 and all possible keys k2, thereby doubling the effective key length. In the case of DES, this would result in a key length of 112 which is plenty large enough to make a full enumeration of the key space infeasible.
Unfortunately, double encryption does not increase the security of a cryptosystem as much as one might naively think. The reason is that it allows new kinds of attacks that are more efficient than brute force.
We consider two cases: When the underlying cryptosystem is a group, and when it is not. DES has been shown not to be a group.
Double encryption is really a new cryptosystem created by composing two encryption functions. Let
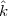 = (k1,k2) be the key of the double encryption system, and let Êk denote the resulting encryption
function, that is,
= (k1,k2) be the key of the double encryption system, and let Êk denote the resulting encryption
function, that is,
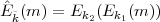
Combining two functions in this way to define a new function is called functional composition. We often
write Ê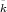 = Ek2 ∘ Ek1 to denote the result of composing Ek2 with Ek1.
= Ek2 ∘ Ek1 to denote the result of composing Ek2 with Ek1.
Let  = {Ek() ∣ k
= {Ek() ∣ k 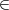
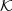 } be the set of possible encryption functions of the original cryptosystem, where
is the key space. It might happen that Ê
} be the set of possible encryption functions of the original cryptosystem, where
is the key space. It might happen that Ê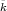 () = Ek() for some k . That is, there might be a key k of the
original cryptosystem such that encrypting any message m with it gives the same ciphertext as
encrypting m first with k1 and then with k2. If this is the case for every k1,k2 , then the
original cryptosystem is said to be closed under functional composition, and we say that it is a
group.
() = Ek() for some k . That is, there might be a key k of the
original cryptosystem such that encrypting any message m with it gives the same ciphertext as
encrypting m first with k1 and then with k2. If this is the case for every k1,k2 , then the
original cryptosystem is said to be closed under functional composition, and we say that it is a
group.
When the cryptosystem is a group, double encryption adds no security against a brute force attack. Even though the key length has doubled, the number of distinct encryption functions has not increased (and might actually have decreased). Since every double encryption is same as a single encryption, the double encryption system will fall to a brute force attack on the original cryptosystem.
But it’s even worse. If a cryptosystem system is a group, then it is subject to a known plaintext “birthday”
attack,1
which reduces the number of keys that must be tried to roughly the square root of what a brute force attack
needs. For example, if the original key length was 56, then only about 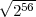 = 228 keys need be
tried.
= 228 keys need be
tried.
Briefly, here’s how it works: Let (m,c) be a known plaintext-ciphertext pair. Choose 228 random keys k1 and encrypt m using each. Choose another 228 random keys k2 and decrypt c using each. Look for a match between these two sets. Assuming reasonable randomness properties of the encryption function, there is a significant probability of finding k1 and k2 such that Ek1(m) = Dk2(c). But this implies that Ek2(Ek1(m)) = c. In this case, we have succeeded in finding one key pair that works. In all likelihood there are not many pairs that do work, so with significant probability we have cracked the system. Using additional plaintext-ciphertext pairs, we can verify that we have likely found the correct key pair, or repeat this process again if we have not yet succeeded. I’ve glossed over many assumptions and details, but that’s the basic idea.
The drawback to the birthday attack (from the attacker’s perspective) is that it requires a lot of storage in order to find a matching element. Nevertheless, if DES were a group, this attack could be carried out in about a gigabyte of storage, easily within the storage capacity of modern workstations.
Even if the original system is not a group, double encryption still does not result in a cryptosystem with twice the effective key length. The reason is another “birthday”-style known-plaintext attack.
Let’s consider the case of double DES. As before, we start with a known plaintext-ciphertext pair (m,c). We carry out a birthday attack by encrypting m under many different keys, decrypting c under many different keys, and hope we find a matching element in the resulting two sets. Unlike the attack described in section 26.1, we encrypt m and decrypt c using all possible DES keys. Thus, we are guaranteed of finding at least one match, since if (k1,k2) is the real key pair used in the double encryption, then Ek1(m) = Dk2(c). If there is only one match, then we have found the key pair and broken the system. If there are several matches, we know that the key pair is one of the matching pairs. This set is likely to be much much smaller than 256, so they can each be tried on additional plaintext-ciphertext pairs to find which ones work. (Note that there might be more than one key pair that results in the same encryption function. In that case, we won’t be able to know which key pair Alice actually used in generating the ciphertexts, but we will be able to find a pair that is just as good and that lets us decrypt her messages.)
Three key triple DES (3TDES) avoids the birthday attack by using three DES encryptions, i.e., Ek3(Ek2(Ek1(m))), giving it an actual key length of 168 bits. While considerably more secure than single DES, for which a brute force attack requires only 256 decryptions, 3TDES can be broken (in principle) by a known plaintext attack using about 290 single DES encryptions and 2113 steps. While this attack is still not practical, the effective security thus lies in the range between 90 and 113, which is much smaller than the apparent 168 bits.2
A variant of triple DES in which the middle step is a decryption instead of an encryption is known as TDES-EDE, i.e., Ek3(Dk2(Ek1(m))). The variant does not affect the security, but it means that TDES-EDE encryption and decryption functions can be used to perform single DES encryptions and decryptions by taking k1 = k2 = k3 = k, where k is the single DES key.
Another variant, two key triple DES (2TDES) uses only two keys k1 and k2, taking k3 = k1. However, known plaintext attacks or chosen plaintext attacks reduce the effective security to only 80 bits. See Wikipedia for further information on triple DES.
A b-bit block cipher takes as inputs a key and a b-bit plaintext block and produces a b-bit ciphertext block as output. Most of the ciphers we have been discussing so far are of this type. Block ciphers typically operate on fairly long blocks, e.g., 64-bits for DES, 128-bits for Rijndael (AES). Block ciphers can be designed to resist known-plaintext attacks and can therefore be pretty secure, even if the same key is used to encrypt a succession of blocks, as is often the case.
Of course, the length messages one wants to send are rarely exactly the block length. To use a block cipher to encrypt long messages, one first divides the message into blocks of the right length, padding the last partial block according to a suitable padding rule. Then the block cipher is used in some chaining mode to encrypt the sequence of resulting blocks. A chaining mode tells how to encrypt a sequence of plaintext blocks m1,m2,…,mt to produce a corresponding sequence of ciphertext blocks c1,c2,…,ct, and conversely, how to recover the mi’s given the ci’s.
Padding involves more than just sticking 0’s on the end of a message until its length is a multiple of the block length. The reason is that one must be able to recover the original message from the padded version. If one tacks on a variable number of 0’s during padding, how many are to be removed at the end? To solve this problem, a padding rule must include the information about how much padding was added. There are many ways to do this. One way is to pad each message with a string of 0’s followed by a fixed-length binary representation of the number of 0’s added. For example, if the block length is 64, then at most 63 0’s ever need to be added, so a 6-bit length field is sufficient. A message m is then padded to become m′ = m ⋅ 0k ⋅k, where k is a number in the range [0,63] and k is its representation as a 6-bit binary number. k is then chosen so that ∣m′∣ = ∣m∣ + k + 6 is a multiple of b.
Some standard chaining modes are: