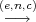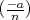YALE UNIVERSITY
DEPARTMENT OF COMPUTER SCIENCE
| CPSC 467a: Cryptography and Computer Security | Notes 22 (rev. 1) | |
| Professor M. J. Fischer | November 30, 2006 | |
Lecture Notes 22
In the locked box coin-flipping protocol, Alice has two messages m0 and m1. Bob gets one of them. Alice doesn’t know which (until Bob tells her). Bob can’t cheat to get both messages. Alice can’t cheat to learn which message Bob got. The oblivious transfer problem abstracts these properties from particular applications such as coin flipping and card dealing,
Alice has a secret s. In an oblivious transfer protocol, half of the time Bob learns s and half of the time he learns nothing. Afterwards, Alice doesn’t know whether or not Bob learned s. Bob can do nothing to increase his chances of getting s, and Alice can do nothing to learn whether or not Bob got her secret. Rabin proposed an oblivious transfer protocol based on quadratic residuosity, shown in Figure 1, in the early 1980’s.
Alice can can carry out step 3 since she knows the factorization of n and can find all of the square roots of a. However, she has no idea which x Bob used to generate a. Hence, with probability 1∕2, y ≡±x (mod n) and with probability 1∕2, y ⁄≡±x (mod n). If y ⁄≡±x (mod n), then the two factors of n are gcd(x - y,n) and n∕gcd(x - y,n), so Bob factors n and decrypts c in step 4. However, if y ≡±x (mod n), he learns nothing, and Alice’s secret is as secure as RSA itself.
There is one potential problem with this protocol. A cheating Bob in step 2 might send a number a which he generated by some other means than squaring a random x. In this case, he learns something new no matter which square root Alice sends him in step 3. Perhaps that information, together with what he already learned in the course of generating a, is enough for him to factor n. We don’t know of any method by which Bob could find a quadratic residue without also knowing one of its square roots. We certainly don’t know of any method that would produce a quadratic residue a and some other information Ξ that, combined with y, would allow Bob to factor n. But we also cannot prove that no such method exists.
We can fix this protocol by inserting between steps 2 and 3 a zero knowledge proof that Bob knows a square root of a. This is essentially what the simplified Feige-Fiat-Shamir protocol does, but we have to reverse the roles of Alice and Bob. Now Bob is the one with the secret square root x. He wants to prove to Alice that he knows x, but he does not want Alice to get any information about x, since if she learns x, she could choose y = x and reduce his chances of learning s while still appear to be playing honestly. Again, details are left to the reader.
In the one-of-two oblivious transfer, Alice has two secrets, s0 and s1. Bob always gets exactly one of the secrets. He gets each with probability 1/2, and Alice does not know which he got.
The locked box protocol is one way to implement one-of-two oblivious transfer. Another is based on a public key cryptosystem (such as RSA) and a symmetric cryptosystem (such as AES). This protocol, given in Figure 2, does not rely on the cryptosystems being commutative.
|
|
In step 2, Bob encrypts a randomly chosen key k for the symmetric cryptosystem using one of the PKS encryption keys that Alice sent him in step 1. In step 2, Bob selects one of the two encryption keys from Alice, uses it to encrypt k, and sends the encryption to Alice. In step 3, Alice decrypts c using both decryption keys d0 and d1 to get k0 and k1. One of the ki is Bob’s key k (kb to be specific) and the other is garbage, but because k is random and she doesn’t know b, she can’t tell which is k. She then encrypts one secret with k0 and the other with k1, using the random bit b′ to ensure that each secret is equally likely to be encrypted by the key that Bob knows. In step 4, Bob decrypts the ciphertext cb using key his key k = kb to recover the secret s = sb⊕b′. He can’t decrypt the other ciphertext c1⊕b since he doesn’t know the key k1⊕b used to produce it, nor does he know the decryption key d1⊕b that would allow him to find it from c.
We mentioned pseudorandom sequence generation in section 29 of lecture notes 6 and section 105 of
lecture notes 21. In a little more detail, a pseudorandom sequence generator G is a function from a domain
of seeds 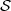 to a domain of strings
to a domain of strings 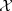 . We will generally find it convenient to assume that all of the seeds in
have the same length m and that all of the strings in have the same length n, where m ≪ n and n is
polynomially related to m.
. We will generally find it convenient to assume that all of the seeds in
have the same length m and that all of the strings in have the same length n, where m ≪ n and n is
polynomially related to m.
Intuitively, we want the strings G(s) to “look random”. But what does that mean? Chaitin and Kolmogorov proposed ways of defining what it means for an individual sequence to be considered random. While philosophically very interesting, these notions are somewhat different than the statistical notions that most people mean by randomness.
We take a different tack. We assume that the seeds are chosen uniformly at random from , that is, we
consider a uniformly distributed random variable S over . Then X = G(S) is a random variable over .
For x 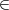 ,
,
![∣{s-∈-S-∣ G-(s)-=-x}∣-
prob[X = x] = ∣S∣ .](ln228x.png)
That is, the probability is the fraction of seeds that give rise to x. Because m ≪ n, ∣∣ = 2m, and
∣∣ = 2n, most strings in are not in the range of G and hence have probability 0. If G happens to be
one-to-one, then the remaining strings each have probability 1∕2m.
We also consider the uniform random variable U , where U = x with probability 1∕2n for every
x . U is what we usually mean by a “truly random” variable on n-bit strings.
We will say that G is a cryptographically strong pseudorandom sequence generator if X and U are indistinguishable to all probabilistic polynomial Turing machines. We have already seen that the probability distributions of X and U are quite different. Nevertheless, they are indistinguishable if there is no feasible algorithm to determine whether random samples come from X or from U.
Before going further, let me describe some functions G for which G(S) is readily distinguished from U. Suppose every string x = G(s) has the form b1b1b2b2b3b3…, for example 0011111100001100110000. . . . An algorithm that guesses that x came from G(S) if x is of that form, and guesses that x came from U otherwise, will be right almost all of the time. True, it is possible to get a string like this from U, but it is extremely unlikely.
Formally speaking, a judge is a probabilistic Turing machine J that takes an n-bit string as input and
produces a single bit b as output. Because it is probabilistic, it actually defines a random function from to
{0,1}. This means that for every input x, there is some probability px that the output is 1. If the input string
is itself a random variable X, then the probability that the output is 1 is the weighted sum
over all possible inputs that the judge outputs 1, where the weights are the probabilities of the
corresponding inputs occurring. Thus, the output value is itself a random variable which we denote by
J(X).
Now, we say that two random variables X and Y are ε-indistinguishable by judge J if
![∣prob[J(X ) = 1]- prob[J(Y ) = 1]∣ < ε.](ln229x.png)
Intuitively, we say that G is cryptographically strong if G(S) and U are ε-indistinguishable for suitably small ε by all judges that do not run for too long. A careful mathematical treatment of the concept of indistinguishability must relate the length parameters m and n, the error parameter ε, and the allowed running time of the judges, all of which is beyond the scope of this course.
[Note: The topics covered by these lecture notes are presented in more detail and with greater mathematical rigor in handout 15.]
We present a cryptographically strong pseudorandom sequence generator BBS, due to Blum, Blum, and
Shub. BBS is defined by a Blum integer n and an integer ℓ. It maps strings in Z*n to strings in {0,1}ℓ.
Given a seed s0 Z*n, we define a sequence s1,s2,s3,…,sℓ, where si = si-12 mod n for i = 1,…,ℓ. The
ℓ-bit output sequence BBS(s0) is b1,b2,b3,…,bℓ , where bi = lsb(si).
The security of BBS is based on the difficulty of determining, for a given a Z*n with Jacobi symbol
 = 1, whether or not a is a quadratic residue, i.e., whether or not a QRn. Recall from section 66 of
lecture notes 12, that this is the property upon on which the security of the Goldwasser-Micali probabilistic
encryption system relies.
= 1, whether or not a is a quadratic residue, i.e., whether or not a QRn. Recall from section 66 of
lecture notes 12, that this is the property upon on which the security of the Goldwasser-Micali probabilistic
encryption system relies.
Blum integers were introduced in section 95 of lecture notes 19. Recall that a Blum prime is a prime p
such p ≡ 3 (mod 4), and a Blum integer is a number n = pq, where p and q are distinct Blum primes.
Blum primes and Blum integers have the important property that every quadratic residue a has exactly
one square root y which is itself a quadratic residue. We call such a y the principal square
root of a and denote it by 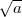 (mod n) or simply by
(mod n) or simply by 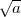 when it is clear that (mod n) is
intended.
when it is clear that (mod n) is
intended.
We need two other facts about Blum integers n.
Proof: This follows from the fact that if a is a quadratic residue modulo a Blum prime, then -a is a quadratic non-residue. Hence,
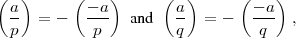
so
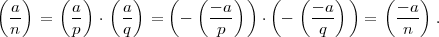
__
Let lsb(x) be the least significant bit of integer x. That is, lsb(x) = (x mod 2).
We begin our proof that BBS is cryptographically strong by showing that there is no probabilistic polynomial time algorithm A that, given b2,…,bℓ, is able to predict b1 with accuracy greater than 1∕2 + ε. This is not sufficient to establish that the pseudorandom sequence BBS(S) is indistinguishable from the uniform random sequence U, but if it did not hold, there certainly would exist a distinguishing judge. Namely, the judge that outputs 1 if b1 = A(b2,…,bℓ) and 0 otherwise would output 1 with probability greater than 1∕2 + ε in the case that the sequence came from BBS(S) and would output 1 with probability exactly 1∕2 in the case that the sequence was truly random.
We now show that if a probabilistic polynomial time algorithm A exists for predicting b1 with accuracy greater than 1∕2 + ε, then there is a probabilistic polynomial time algorithm Q for testing quadratic residuosity with the same accuracy. Thus, if quadratic-residue-testing is “hard”, then so first-bit prediction for BBS.1
Theorem 1 Let A be a first-bit predictor for BBS(S) with accuracy 1∕2 + ε. Then we can find an algorithm Q for testing whether a number x with Jacobi symbol 1 is a quadratic residue, and Q will be correct with probability at least 1∕2 + ε.
QRn and 0 to
mean x ⁄ QRn. |
| ||||||||||||||||
Since  = 1, then either x or -x is a quadratic residue. Let s0 be the principal square root of x or
-x. Let s1,…,sℓ be the state sequence and b1,…,bℓ the corresponding output bits of BBS(s0). We have
two cases.
= 1, then either x or -x is a quadratic residue. Let s0 be the principal square root of x or
-x. Let s1,…,sℓ be the state sequence and b1,…,bℓ the corresponding output bits of BBS(s0). We have
two cases.
Case 1: x QRn. Then s1 = x, so the state sequence of BBS(s0) is

and the corresponding output sequence is

Since  1 = b1, Q(x) correctly outputs 1 whenever A correctly predicts b1. This happens with probability at
least 1∕2 + ε.
1 = b1, Q(x) correctly outputs 1 whenever A correctly predicts b1. This happens with probability at
least 1∕2 + ε.
Case 2: x QNRn, so -x QRn. Then s1 = -x, so the state sequence of BBS(s0) is

and the corresponding output sequence is

Since 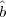 1 = ¬b1, Q(x) correctly outputs 0 whenever A correctly predicts b1. This happens with probability
at least 1∕2 + ε.
1 = ¬b1, Q(x) correctly outputs 0 whenever A correctly predicts b1. This happens with probability
at least 1∕2 + ε.
In both cases, Q(x) gives the correct output with probability at least 1∕2 + ε. __