![prob[A (b1,...,bi-1) = bi] ≥ 1+ ε
2](ln240x.png)
YALE UNIVERSITY
DEPARTMENT OF COMPUTER SCIENCE
| CPSC 467a: Cryptography and Computer Security | Notes 24 (rev. 2) | |
| Professor M. J. Fischer | December 7, 2006 | |
Lecture Notes 24
One important property of the uniform distribution U on bit-strings b1,…,bℓ is that the individual bits are statistically independent from each other. This means that the probability that a particular bit bi = 1 is unaffected by the values of the other bits in the sequence. Thus, any algorithm that attempts to predict bi, even knowing other bits of the sequence, will be correct only 1/2 of the time. We now translate this property of unpredictability to pseudorandom sequences.
One property we would like a pseudorandom sequence to have is that it be difficult to predict the next bit given the bits that came before.
We say that an algorithm A is an ε-next-bit predictor for bit i of a PRSG G if
where (b1,…,bi) = Gi(S). To explain this notation, S is a uniformly distributed random variable ranging over the possible seeds for G. G(S) is a random variable (i.e., probability distribution) over the output strings of G, and Gi(S) is the corresponding probability distribution on the length-i prefixes of G(S).
Next-bit prediction is closely related to indistinguishability, introduced in section 110. We will show later that if if G(S) has a next-bit predictor for some bit i, then G(S) is distinguishable from the uniform distribution U on the same length strings, and conversely, if G(S) is distinguishable from U, then there is a next-bit predictor for some bit i of G(S). The precise definitions under which this theorem is true are subtle, for one must quantify both the amount of time the judge and next-bit predictor algorithms are permitted to run as well as how much better than chance the judgments or predictions must be in order to be considered a successful judge or next-bit predictor. We defer the mathematics for now and focus instead on the intuitive concepts that underlie this theorem.
Suppose a PRSG G has an ε-next-bit predictor A for some bit i. Here’s how to build a judge J that distinguishes G(S) from U. The judge J, given a sample string drawn from either G(S) or from U, runs algorithm A to guess bit bi from bits b1,…,bi-1. If the guess agrees with the real bi, then J outputs 1 (meaning that he guesses the sequence came from G(S)). Otherwise, J outputs 0. For sequences drawn from G(S), J will output 1 with the same probability that A successfully predicts bit bi, which is at least 1∕2 + ε. For sequences drawn from U, the judge will output 1 with probability exactly 1/2. Hence, the judge distinguishes G(S) from U with advantage ε.
It follows that no cryptographically strong PRSG can have an ε-next-bit predictor. In other words, no algorithm that attempts to predict the next bit can have more than a “small” advantage ε over chance.
Previous-bit prediction, while perhaps less natural, is analogous to next-bit prediction. An ε-previous-bit predictor for bit i is an algorithm that, given bits bi+1,…,bℓ, correctly predicts bi with probability at least 1∕2 + ε.
As with next-bit predictors, it is the case that if G(S) has a previous-bit predictor for some bit bj, then some judge distinguishes G(S) from U. Again, I am being vague with the exact conditions under which this is true. The somewhat surprising fact follows that G(S) has an ε-next-bit predictor for some bit i if and only if it has an ε′-previous-bit predictor for some bit j (where ε and ε′ are related but not necessarily equal).
To give some intuition into why such a fact might be true, we look at the special case of ℓ = 2, that is, of 2-bit sequences. The probability distribution G(S) can be described by four probabilities
![p = prob[b = u∧ b = v], where u, v ∈ {0,1}.
u,v 1 2](ln241x.png)
Written in tabular form, we have
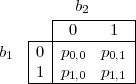
We describe an algorithm A(v) for predicting b1 given b2 = v. A(v) predicts b1 = 0 if p0,v > p1,v, and it predicts b1 = 1 if p0,v ≤ p1,v. In other words, the algorithm chooses the value for b1 that is most likely given that b2 = v. Let a(v) be the value predicted by A(v).
Theorem 1 If A is an ε-previous-bit predictor for b1, then A is an ε-next-bit predictor for either b1 or b2.
Proof: Assume A is an ε-previous-bit predictor for b1. Then A correctly predicts b1 given b2 with probability at least 1∕2 + ε. We show that A is an ε-next-bit predictor for either b1 or b2.
We have two cases:
Case 1: a(0) = a(1). Then algorithm A does not depend on v, so A itself is also an ε-next-bit predictor for b1.
Case 2: a(0)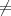 a(1). The probability that A(v) correctly predicts b1 when b2 = v is given by the
conditional probability
a(1). The probability that A(v) correctly predicts b1 when b2 = v is given by the
conditional probability
![prob[b1 = a(v) ∣ b2 = v ] = prob[b1 =-a(v)-∧b2-=-v]=-pa(v),v--
prob[b2 = v] prob[b2 = v]](ln244x.png)
The overall probability that A(b2) is correct for b1 is the weighted average of the conditional probabilities for v = 0 and v = 1, weighted by the probability that b2 = v. Thus,
![∑
prob[A(b2) is correct for b1] = prob[b1 = a(v) ∣ b2 = v]⋅prob[b2 = v ]
v∈{0,1}
∑
= pa(v),v
v∈{0,1}
= pa(0),0 + pa(1),1](ln245x.png)
Now, since a(0)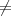 a(1), the function a is one-to-one and onto. A simple case analysis shows that either
a(v) = v for v
a(1), the function a is one-to-one and onto. A simple case analysis shows that either
a(v) = v for v 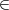 {0,1}, or a(v) = ¬v for v {0,1}. That is, a is either the identity or the complement
function. In either case, a is its own inverse. Hence, we may also use algorithm A(u) as a predictor for b2
given b1 = u. By a similar analysis to that used above, we get
{0,1}, or a(v) = ¬v for v {0,1}. That is, a is either the identity or the complement
function. In either case, a is its own inverse. Hence, we may also use algorithm A(u) as a predictor for b2
given b1 = u. By a similar analysis to that used above, we get
![prob[A (b ) is correct for b ] = ∑ prob[b = a(u) ∣ b = u]⋅prob[b = u]
1 2 2 1 1
v∈∑{0,1}
= pu,a(u)
v∈{0,1}
= p + p
0,a(0) 1,a(1)](ln247x.png)

since either a is the identity function or the complement function. Hence, A(b1) is correct for b2 with the same probability that A(b2) is correct for b1. Therefore, A is an ε-next-bit predictor for b2.
In both cases, we conclude that A is an ε-next-bit predictor for either b1 or b2. __
[This section is based on the second textbook, John Talbot and Dominic Welsh, Complexity and Cryptograpy: An Introduction, §6.1–6.3.]
We have been rather vague throughout the course about what it means for a problem to be “hard” to solve. A public key system such as RSA can always be broken given enough time. Eve could simply factor n and find the decryption key, or she could try all possible messages m to see which one encrypts to the known ciphertext c given the public encryption key. So we can’t hope to always prevent Eve from decrypting our messages. The best we can hope for is that she rarely succeeds. We can state this as follows:
Goal: If Eve uses a probabilistic polynomial time algorithm, the probability of her successfully decrypting c = Ek(m) for a random message m is negligible.
We have to say what “negligible” means. A function r : ℕ → ℕ is negligible if for all polynomial functions p : ℕ → ℕ, there exists k0 such that for all k ≥ k0,
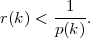
(We assume p(k) ≥ 1 for all integers k ≥ 0.)
This definition says that r(k) → 0 as k →∞. But it says more. It also says that r(k) goes to 0 “faster”
than one over any polynomial. For all large enough k, r(k) is smaller than 1∕k10, for example. It’s
tempting to equate negligible with inverse exponential. While 1∕2k is indeed a negligible function,
there are larger functions that are also negligible by our definitions, for example, 1∕2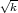 and
1∕klog k.
and
1∕klog k.
Definition: A function f is strong one-way if
By “random instance”, this means a y of the form y = f(x) for a uniformly distributed random x.
Even this definition hides some technical difficulties that are done carefully in the text book. In particular, the difficulty of inverting f should remain hard even when the inverter is told the length of x.
The following function related to the discrete log problem is often assumed to be strong one:
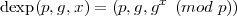
It is easy to compute, but to invert it requires solving the discrete log problem.
Although functions like dexp and factoring are believed to be strong one-way functions, no function
has been proved to be strong one-way. The following theorem explains why it is so hard to prove that
functions are strong one-way – doing so would also settle the famous P = NP? problem by showing that
P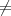 NP .
NP .
Theorem 2 If strong one-way functions exist, then P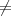 NP .
NP .
Proof: Assume f is strong one-way. Define the language
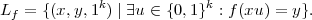
Lf is easily seen to be in NP . To test if a given (x,y,1k) triple is in Lf, simply guess a string u of length k, compute f(xu), and check that f(xu) = y.
If P = NP , then there is a polynomial time algorithm A for testing membership in Lf. A can
be used to determine the bits of a preimage of y one by one. At stage i, assume that the first i-1 bits
xi-1 of a preimage have already been determined. To determine bit i, test if (xi-10,y,1k-i) Lf.
If so, then xi = 0xi-1 are the first i bits of some preimage. If not, then (xi-11,y,1(k - i)) must
be in Lf since xi01 is known to be the prefix of a preimage. Hence, one can take xi = xi-11 in
this case. After stage k, the number xk is a preimage of y, as desired. The entire procedure requires
only k evaluations of A, so it is also a polynomial time algorithm for inverting f, contradicting the
assumption that f is one-way.
We conclude that P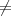 NP if one-way functions exist. __
NP if one-way functions exist. __