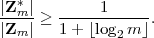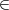 Z*
n if e and d are chosen
so that
Z*
n if e and d are chosen
so that
YALE UNIVERSITY
DEPARTMENT OF COMPUTER SCIENCE
| CPSC 467a: Cryptography and Computer Security | Notes 9 (rev. 1) | |
| Professor M. J. Fischer | October 5, 2006 | |
Lecture Notes 9
We showed in section 42 (lecture notes 8) that RSA decryption works for m Z*
n if e and d are chosen
so that
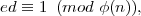 | (1) |
that is, d is e-1 (the inverse of e) in Z*φ(n).
We now turn to the question of how Alice chooses e and d to satisfy (1). One way she can do this is to
choose a random integer e Z*φ(n) and then solve (1) for d. We will show how to do this in Sections 45
and 46 below.
However, there is another issue, namely, how does Alice find random e Z*φ(n)? If Z*φ(n) is large
enough, then she can just choose random elements from Zφ(n) until she encounters one that lies in Z*φ(n).
But how large is large enough? If φ(φ(n)) (the size of Z*φ(n)) is much smaller than φ(n) (the
size of Zφ(n)), she might have to search for a long time before finding a suitable candidate for
e.
In general, Z*m can be considerably smaller than m. For example, if m = ∣Zm∣ = 210, then ∣Z*m∣ = 48. In this case, the probability that a randomly-chosen element of Zm falls in Z*m is only 48∕210 = 8∕35 = 0.228… .
The following theorem provides a crude lower bound on how small Z*m can be relative to the size of Zm that is nevertheless sufficient for our purposes.
Proof: Write m in factored form as m = ∏ i=1tpiei, where pi is the ith prime that divides m and ei ≥ 1. Then φ(m) = ∏ i=1t(pi - 1)piei-1, so
 | (2) |
To estimate the size of ∏ i=1t(pi - 1)∕pi, note that (pi - 1)∕pi ≥ i∕(i + 1). This follows since (x- 1)∕x is monotonic increasing in x, and pi ≥ i + 1. Then
 | (3) |
Clearly t ≤⌊log 2m⌋ since 2t ≤∏ i=1tpi ≤ m and t is an integer. Combining this fact with equations (2) and (3) gives the desired result. __
For n a 1024-bit integer, φ(n) < n < 21024. Hence, log 2(φ(n)) < 1024, so ⌊log 2(φ(n))⌋≤ 1023. By Theorem 1, the fraction of elements in Zφ(n) that also lie in Z*φ(n) is at least 1/1024. Therefore, the expected number of random trials before Alice finds a number in Z*φ(n) is provably at most 1024 and is most likely much smaller.
To test if d Z*φ(n), Alice can test if gcd(d,φ(n)) = 1. How does she do this?
The basic ideas underlying the Euclidean algorithm were sketched in section 40.2 (lecture notes 8). Euclid’s algorithm is remarkable, not only because it was discovered a very long time ago, but also because it works without knowing the factorization of a and b. It relies on the equation
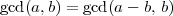 | (4) |
which holds when a ≥ b ≥ 0. This allows the problem of computing gcd(a,b) to be reduced to the problem of computing gcd(a - b,b), which is “smaller” if b > 0. Here we measure the size of the problem (a,b) by the sum a + b of the two arguments. (4) leads in turn leads to an easy recursive algorithm:
int gcd(int a, int b)
{ if ( a < b ) return gcd(b, a); else if ( b == 0 ) return a; else return gcd(a-b, b); } |
Nevertheless, this algorithm is not very efficient, as you will quickly discover if you attempt to use it, say, to compute gcd(1000000,2).
Repeatedly applying (4) to the pair (a,b) until it can’t be applied any more produces the sequence of pairs (a,b),(a-b,b),(a- 2b,b),…,(a-qb,b). The sequence stops when a-qb < b. But the number of times you can subtract b from a is just the quotient ⌊a∕b⌋, and the amount a - qb that is left is just the remainder a mod b. Hence, one can go directly from the pair (a,b) to the pair (a mod b,b). Since a mod b < b, it is also convenient to swap the elements of the pair. This results in the Euclidean algorithm (in C notation):
int gcd(int a, int b)
{ if ( b == 0 ) return a; else return gcd(b, a % b); } |
Now that Alice knows how to choose d Z*φ(n), how does she find e? That is, how does she solve (1)?
Note that e, if it exists, is a multiplicative inverse of d (mod n), that is, a number that, when multiplied by
d, gives 1.
Equation (1) is an instance of the general Diophantine equation
 | (5) |
Here, a,b,c are given integers. A solution consists of integer values for the unknowns x and y. To put (1) into this form, we note that ed ≡ 1 (mod φ(n)) iff ed + uφ(n) = 1 for some integer u. This is seen to be an equation in the form of (5) where the unknowns x and y are e and u, respectively, and the coefficients a,b,c are d, φ(n), and 1, respectively.
It turns out that (5) is closely related to the greatest common divisor, for it has a solution iff gcd(a,b)∣c. It can be solved by a process akin to the Euclidean algorithm, which we call the Extended Euclidean algorithm. Here’s how it works.
The algorithm generates a sequence of triples of numbers Ti = (ri,ui,vi), each satisfying the invariant
 | (6) |
The first triple T1 is (a,1,0) if a ≥ 0 and (-a,-1,0) if a < 0. The second trip T2 is (b,0,1) if b ≥ 0 and (-b,0,-1) if b < 0.
The algorithm generates Ti+2 from Ti and Ti+1 much the same as the Euclidean algorithm generates (a mod b) from a and b. More precisely, let qi+1 = ⌊ri∕ri+1⌋. Then Ti+2 = Ti - qi+1Ti+1, that is,
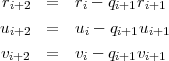
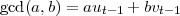 | (7) |
Returning to equation (5), if c = gcd(a,b), then x = ut-1 and y = vt-1 is a solution. If c is a multiple of gcd(a,b), then c = k gcd(a,b) for some k and x = kut-1 and y = kvt-1 is a solution. Otherwise, gcd(a,b) does not divide c, and one can show that (5) has no solution. See Handout 5 for further details, as well as for a discussion of how many solutions (5) has and how to find all solutions.
Here’s an example. Suppose one wants to solve the equation
 | (8) |
In this example, a = 31 and b = -45. We begin with the triples


From T7 = (1,16,11) and (6), we obtain
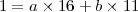
Plugging in values a = 31 and b = -45, we compute
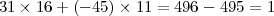
as desired. The solution to (8) is then x = 3 × 16 = 48 and y = 3 × 11 = 33.
We finally turn to the question of generating the RSA modulus, n = pq. Recall that the numbers p and q should be random distinct primes of about the same length. The method for finding p and q is similar to the “guess-and-check” method used in Section 43 to find random numbers in Z*n. Namely, keep generating random numbers p of the right length until a prime is found. Then keep generating random numbers q of the right length until one is found that is prime and different from p.
To generate a random prime of a given length, say k bits long, generate k - 1 random bits, put a “1” at the front, regard the result as binary number, and test if it is prime. We defer the question of how to test if the number is prime and look now at the expected number of trials before this procedure will terminate.
The above procedure samples uniformly from the set Bk = Z2k - Z2k-1 of binary numbers of length exactly k. Let pk be the fraction of elements in Bk that are prime. Then the expected number of trials to find a prime will be 1∕pk. While pk is difficult to determine exactly, the celebrated Prime Number Theorem allows us to get a good estimate on that number.
Let π(n) be the number of numbers ≤ n that are prime. For example, π(10) = 4 since there are four primes ≤ 10, namely, 2, 3, 5, 7. The prime number theorem asserts that π(n) is “approximately”2 n∕(lnn), where lnn is the natural logarithm (log e) of n. The chance that a randomly picked number in Zn is prime is then π(n - 1)∕n ≈ ((n - 1)∕ln(n - 1))∕n ≈ 1∕(lnn).
Since Bk = Z2k - Z2k-1, we have

The remaining problem for generating an RSA key is how to test if a large number is prime. Until very recently, no deterministic polynomial time algorithm was known for testing primality, and even now it is not known whether any deterministic algorithm is feasible in practice. However, there do exist fast probabilistic algorithms for testing primality, which we now discuss
A deterministic test for primality is a procedure that, given as input a number n, correctly returns the answer ‘composite’ or ‘prime’.3 To arrive at a probabilistic algorithm, we extend the notion of a deterministic primality test in two ways: We give it an extra “helper” string a, and we allow it to answer ‘?’, meaning “I don’t know”. Given input n and helper string a, such an output may correctly answer either ‘composite’ or ‘?’ when n is composite, and it may correctly answer either ‘prime’ or ‘?’ when n is prime. If the algorithm gives a non-”?” answer, we say that the helper string a is a witness to that answer.
Given an extended primality test T(n,a), we can use it to build a strong probabilistic primality testing algorithm. On input n, do the following:
| Algorithm P1(n): |
| repeat forever { |
| Generate a random helper string a; |
| Let r = T(n,a); |
if (r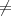 ‘?’) return r; ‘?’) return r; |
| }; |
This algorithm has the property that it might not terminate (in case there are no witnesses to the correct answer for n), but when it does terminate, the answer is correct.
Unfortunately, we do not know of any test that results in an efficient strong probabilistic primality testing algorithm. However, the above algorithm can be weakened slightly and still be useful. What we do is to add a parameter t which is the maximum number of trials that we are willing to perform. The algorithm then becomes:
| Algorithm P2(n,t): |
| repeat t times { |
| Generate a random helper string a; |
| Let r = T(n,a); |
if (r ‘?’) return r; ‘?’) return r; |
| } |
| return ‘?’; |
Now the algorithm is allowed to give up and return ‘?’, but only after trying t times to find the correct answer. If there are lots of witnesses to the correct answer, then the probability will be high of finding one, so most of the time the algorithm will succeed. But even this assumption is stronger than we know how to achieve.
The tests that we will present are asymmetric. When n is composite, there are many witnesses to that effect, but when n is prime, there are none. Hence, the test either outputs ‘composite’ or ‘?’ but never ‘prime’. We call these tests of compositeness since an answer of ‘composite’ means that n is definitely composite, but these tests can never say for sure that n is prime.
When algorithm P2 uses a test of compositeness, an answer of ‘composite’ likewise means that n is definitely composite. Moreover, if there are many witnesses to n’s being composite and t is sufficiently large, then the probability that P2(n,t) outputs ‘composite’ will be high. However, if n is prime, then both the test and P2 will always output ‘?’. It is tempting to interpret P2’s output of ‘?’ to mean “n is probably prime”, but of course, it makes no sense to say that n is probably prime; n either is or is not prime. But what does make sense is to say that the probability is very small that P2 answers ‘?’ when n is composite.
In practice, we will indeed interpret the output ‘?’ to mean ‘prime’, but we understand that the algorithm has the possibility of giving the wrong answer when n is composite. Whereas before our algorithm would only report an answer when it was sure and would answer ‘?’ otherwise, now we are considering algorithms that are allowed to make mistakes with (hopefully) small probability.